
Unsupervised Learning is a branch of Machine Learning that deals with the analysis of unlabeled data. In this blog post, we will discuss the principles of Unsupervised Learning, its key algorithms, and its applications.
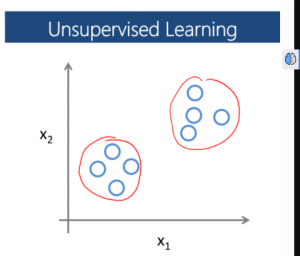
What is Unsupervised Learning?
- Unsupervised Learning focuses on discovering hidden patterns, structures, or relationships in data without the guidance of labeled examples.
- The primary goal of Unsupervised Learning is to gain insights into the underlying structure of the data and identify meaningful patterns.
Popular Unsupervised Learning Algorithms:
- Clustering: Grouping similar instances based on their features, with algorithms such as K-Means, DBSCAN, or Hierarchical Clustering.
- Dimensionality Reduction: Reducing the number of features while preserving the essential information, with techniques like Principal Component Analysis (PCA) or t-Distributed Stochastic Neighbor Embedding (t-SNE).
- Association Rule Mining: Finding relationships between variables in large datasets, often used for market basket analysis.
Applications of Unsupervised Learning:
- Customer Segmentation: Grouping customers based on their purchasing behavior, demographics, or preferences to tailor marketing strategies.
- Anomaly Detection: Identifying unusual instances or outliers in data, such as fraudulent transactions or network intrusions.
- Data Compression: Reducing the storage requirements and computational complexity of large datasets while preserving the essential information.
Challenges and Future Directions:
- Choosing appropriate distance or similarity measures for clustering and other unsupervised tasks.
- Handling high-dimensional data and the “curse of dimensionality.”
- Developing unsupervised algorithms that are robust to noise, outliers, and varying data distributions.
0 Comments