
Supervised Learning is a core technique in Machine Learning that focuses on learning from labeled datasets. In this blog post, we will discuss the principles of Supervised Learning, its popular algorithms, and its applications.
What is Supervised Learning?
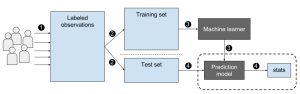
- Supervised Learning is a Machine Learning technique where an algorithm learns the relationship between input features and output labels from a labeled dataset.
- The primary goal of Supervised Learning is to create a model that generalizes well to unseen data, making accurate predictions on new instances.
Popular Supervised Learning Algorithms:
- Linear Regression: A simple method for predicting a continuous target variable based on one or more input features.
- Logistic Regression: A method for binary classification that models the probability of an instance belonging to a particular class.
- Decision Trees: A hierarchical model that makes decisions based on a series of binary decisions on input features.
Applications of Supervised Learning:
- Predictive Analytics: Forecasting sales, stock prices, or other numeric values.
- Image Classification: Assigning labels to images based on their content.
- Spam Detection: Identifying spam emails based on their text and metadata.
Challenges and Future Directions:
- Overfitting and underfitting: Balancing model complexity to achieve accurate predictions without memorizing the training data.
- Feature engineering: Selecting the most relevant input features to improve model performance.
- Handling imbalanced datasets: Ensuring accurate predictions when some classes are underrepresented in the training data.
0 Comments