
Feature Selection is an essential step in the Machine Learning pipeline that involves selecting the most relevant features from the dataset for a specific task. In this blog post, we will discuss the importance of Feature Selection, its techniques, and its impact on model performance.
Why is Feature Selection Important?
- Feature Selection helps reduce the dimensionality of the dataset, which can lead to faster model training and improved model generalization.
- By retaining only the most relevant features, models can focus on the underlying patterns and relationships in the data, leading to better performance.
- Feature Selection can also improve model interpretability by reducing the complexity of the model and highlighting the most influential features.
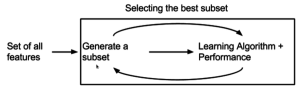
Techniques in Feature Selection:
- Filter Methods: These techniques rank features based on a specific metric, such as correlation or mutual information, and select the top-ranked features. Examples include Pearson correlation and chi-squared test.
- Wrapper Methods: These techniques evaluate feature subsets based on the performance of a specific model, searching for the optimal subset that maximizes model performance. Examples include forward selection, backward elimination, and recursive feature elimination.
- Embedded Methods: These techniques perform feature selection as part of the model training process, incorporating the feature selection step directly into the model construction. Examples include LASSO regression, Ridge regression, and Decision Trees.
Impact of Feature Selection on Model Performance:
- Improved Accuracy: By focusing on the most relevant features, models can learn underlying patterns and relationships in the data more effectively, leading to better performance.
- Reduced Overfitting: Feature Selection helps prevent overfitting by reducing the complexity of the model and eliminating irrelevant or redundant features.
- Faster Training: By reducing the dimensionality of the dataset, Feature Selection can lead to faster model training and convergence.
Challenges and Future Directions:
- Automation: Developing automated feature selection techniques that can streamline the Machine Learning pipeline and reduce reliance on human expertise.
- Scalability: Adapting feature selection techniques to handle large-scale datasets with high-dimensional feature spaces.
- Interpretability: Ensuring that the feature selection process remains interpretable, enabling better understanding of model decision-making processes and feature importance.
0 Comments